In recent months, the term “data lake” has appeared in articles and presentations, most commonly referred to as “data lake”. Our data would no longer be stored in “warehouses” but in the form of lakes. Has there been progress or is it a new marketing concept that will disappear as quickly as it appeared?
Often compared to data warehouses, a data lake is a place where you dump all forms of data generated in various parts of your business: structured data feeds, chat logs, emails, images (of invoices, receipts, checks etc.), and videos.
It is important to understand that data lake and data warehouse have quite a few differences and should not be used the same way.
Let’s first understand what is a Data Lakes and Data Warehouse :
What is a Data Lake :
Data lake is an operational data store that stores a wide variety of raw data in its original form until its needed.
According to Pentaho CTO James Dixon., the one who coined the term Data Lake, describes data mart (a subset of a data warehouse) as akin to a bottle of water…”cleansed, packaged and structured for easy consumption” while a data lake is more like a body of water in its natural state. Data flows from the streams (the source systems) to the lake. Users have access to the lake to examine, take samples or dive in.
A data lake uses a flat architecture for storing data and each data element is given a unique identifier and a set of extended metadata tags.
When a business query arises the data lake can be queried and then the result is analyzed.
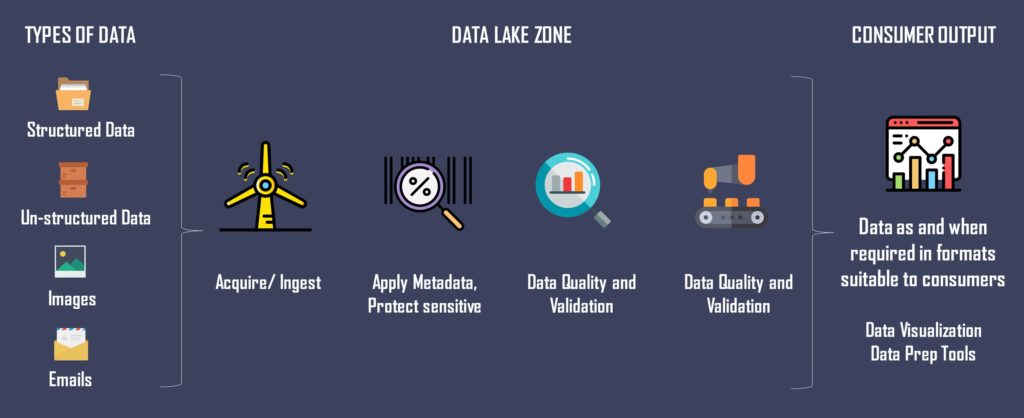
Data Lakes allow you to store relational data—operational databases, and data from a line of business applications, and non-relational data—mobile apps, IoT devices, and social media. The type of data stored in the data lakes is understood through crawling, cataloging, and indexing of data.
Data Lakes provides endless freedom to data scientists, data developers, and business analysts to access a large pool of data with their choice of analytic tools and frameworks like open source frameworks such as Apache Hadoop, Presto, and Apache Spark, and commercial offerings from data warehouse and business intelligence vendors.
In the end, different types of insights can be generated using and different models are built to forecast likely outcomes and suggest a range of prescribed actions to achieve the optimal result.
What is Data warehouse:
In simple term, its a collection of business information and data which is derived from operational systems and external data sources.
Data is populated in the data warehouse through ingestion, transformation, and loading. A data warehouse can help is making various business decisions by allowing the analysis and reporting of the data that is sourced from many heterogeneous sources/channels and stored in a single area.
Unlike an operational data store, a data warehouse contains aggregate historical data, which may be analyzed to reach critical business decisions. Despite associated costs and effort, most major corporations today use data warehouses.
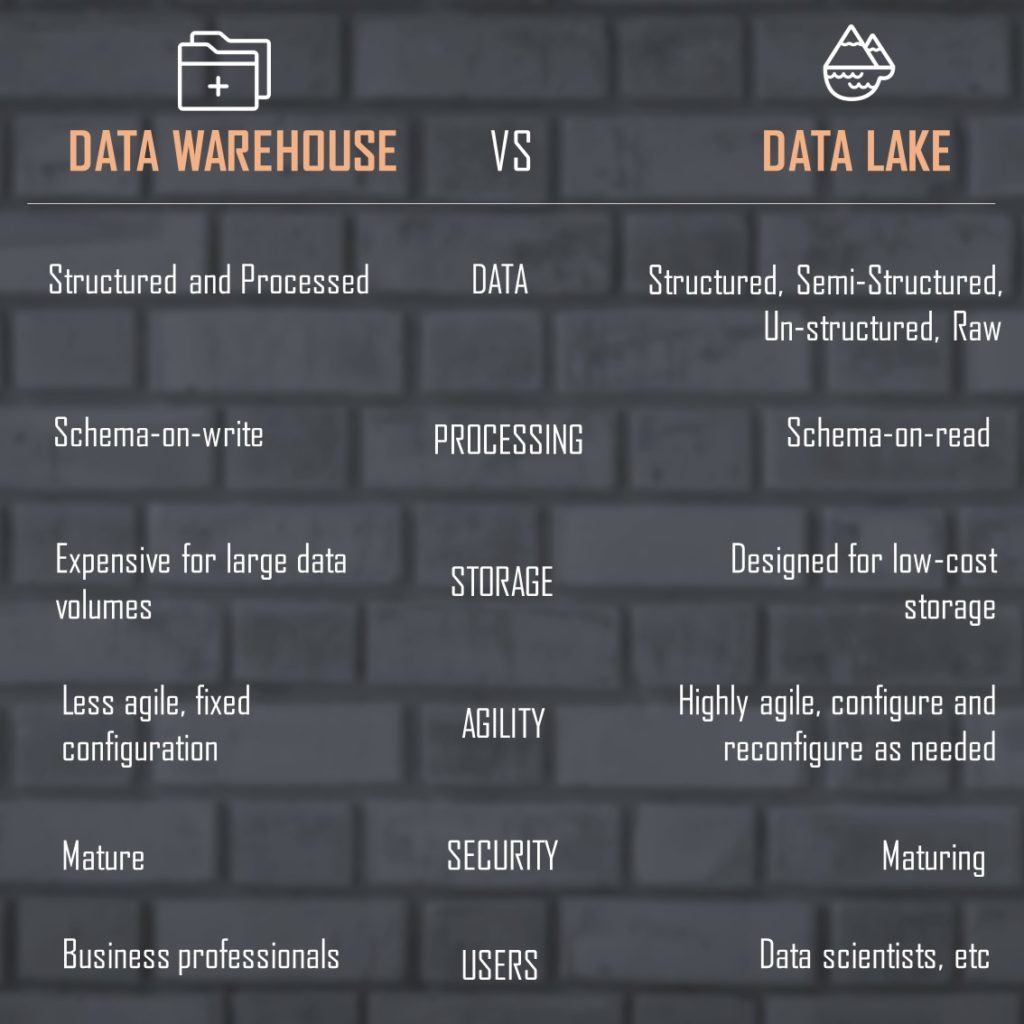
Data Lake VS Data Warehouse :
Where are we Heading?
Being a new field of Computing, which most large corporations do not use yet since their entire IT Landscape (which has been evolving over decades) is necessarily constituted by Systems in “silos” which then interchange Data via API or other interconnect channels, there are several expectations like:
- Can Data Lake ease the burden of ITL? By making it either less time consuming or complex?
- Will we be able to apply several multiple “schemas” over one given Data Lake, simultaneously, and by doing so leveraging multiple “efficiencies” over existing data?
- Will we be able to finally reach “cross-organizational” Data, so instead of having the Data about one given client or partner that Accounting accesses plus other Data about the same 3rd party that Logistics accesses and so on … having a Full Integrated Data Profile about it, which everyone accesses although according to profile permissions? Since the Data Warehouse did not do the trick, isn’t it possible that a Data Lake is just a new name for Data Mart version 2.0?
The entire concept of capturing raw data and applying distinct Schemas to it (logical circumstantial processing) is a very powerful one and in fact, it is precisely what our brain does. We gather raw data and based on our knowledge (rules gathered through past experience and learning) we are able to “issue” a new set of Data that adds value to what we have collected and had stored as “knowledge”.
And this … has everything to do with Artificial Intelligence.
Excerpts of the blog taken from leveraging data lakes article published by https://www.tenfold.com/
Check out https://www.tenfold.com/what-is/leveraging-data-lakes to get detailed insights about what is data lake and how businesses are leveraging it for their own benefit.